
OpenAI’s training crawler was stuck pinging “the world’s lamest content farm” millions of times over the last several days, according to John Levine, the man who wrote The Internet for Dummies and created the site.
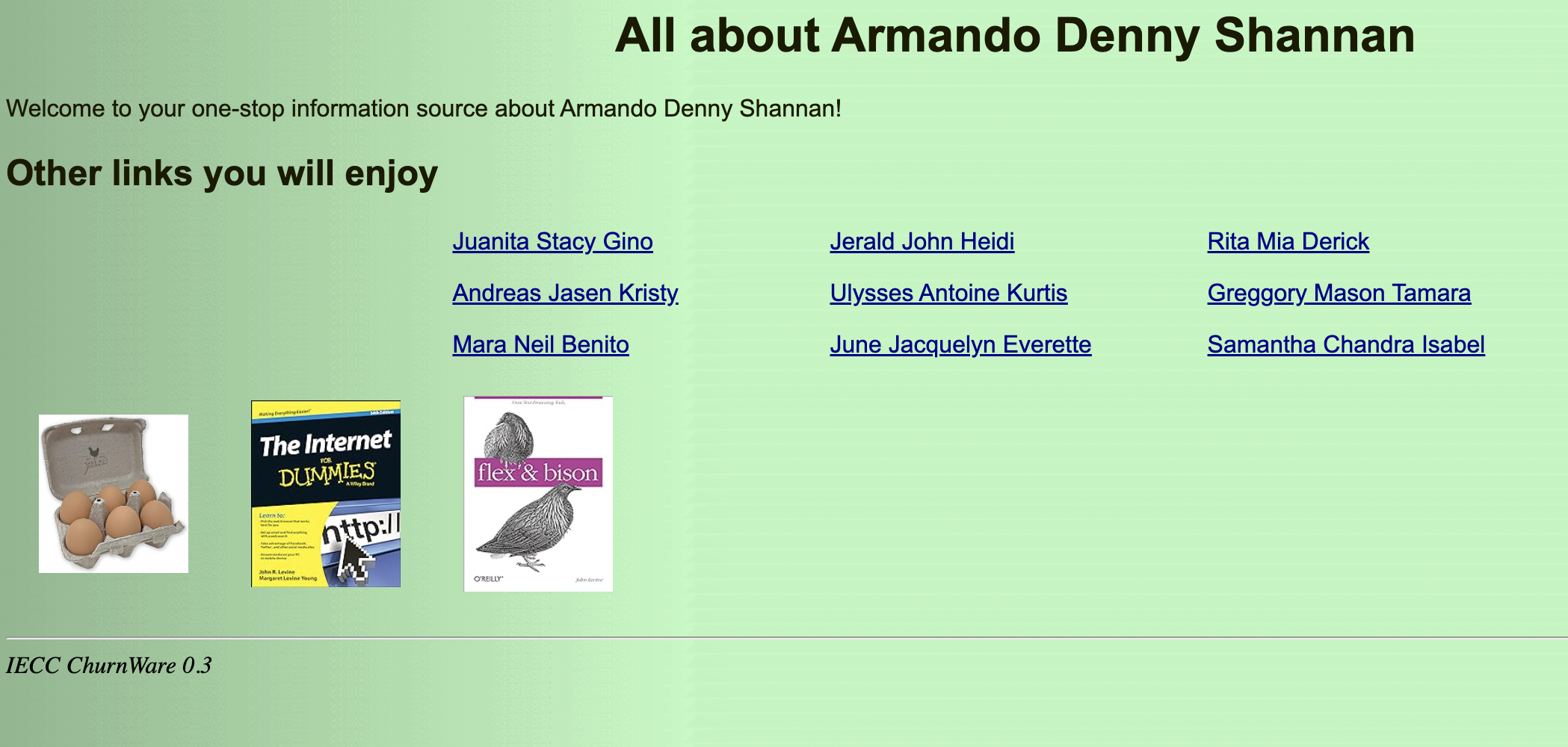
Levine created the content farm as an experiment and it receives extremely few views from humans, he told me. But the design of the site—which is actually a series of billions of single-page connected sites—has proven capable of trapping various web crawlers over the years. The pages, which start at the url web.sp.am/., look like this:
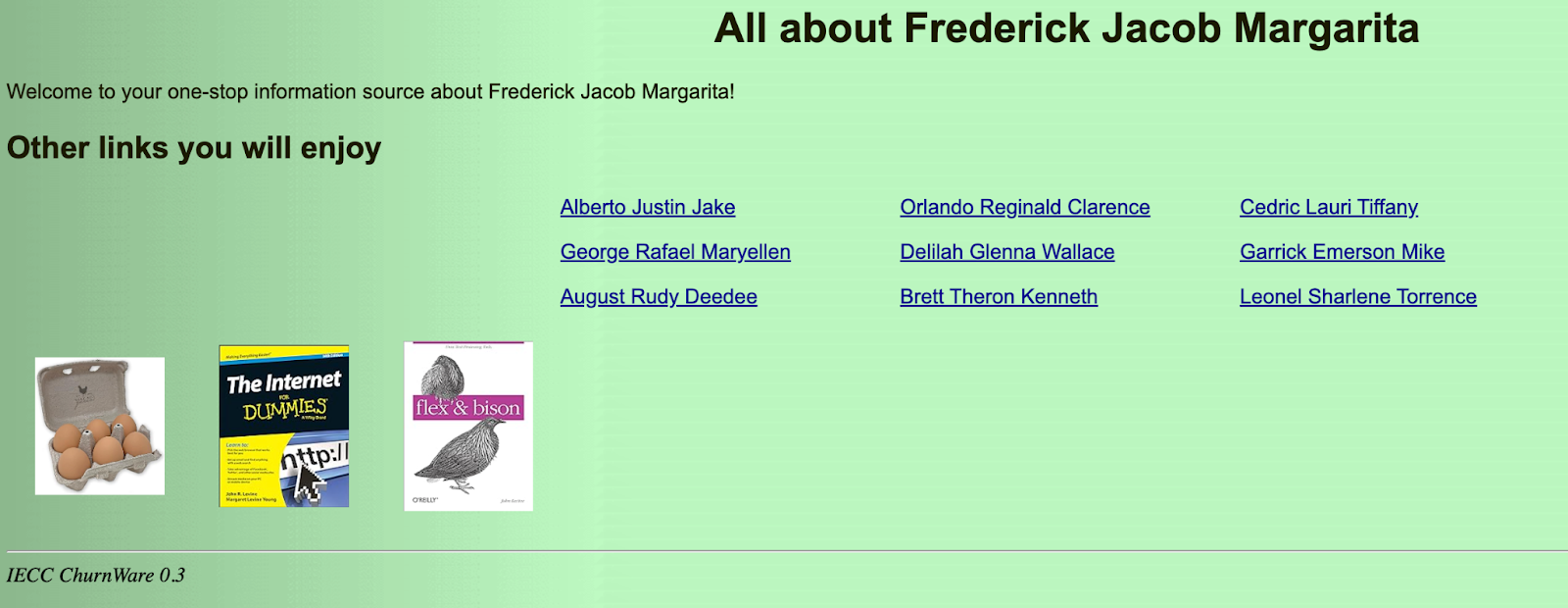
When you click any of these links, you are directed to a page that looks basically identical but has different names. Levine says it was built using a 100-line PERL script he wrote “in an afternoon” that has a database of a few thousand first names. “Each time you click on a page, it picks three of the names and puts that into the domain name,” Levine said. “Based on those names, it uses those as a seed for a random number generator to pick nine more names out of the sets of names in the database. That’s all it does.”
“Rather than being one giant website, each page has its own domain name. A badly written spider, like, for example, OpenAI’s will say ‘Oh look at all these websites that are linked together!’” and will essentially get trapped pinging the sites. At one point Wednesday, OpenAI’s GPTBot was crawling Levine’s site as many as 150 times per second, according to activity logs I viewed. It hit his pages more than 3 million times over the last several days, he said.
Levine posted about the problem on the North American Operators Group listserv, which has been around since 1992 and is for web developers and IT and networking professionals: “Anyone got a contact at OpenAI. They have a spider problem.,” he wrote.
“I have the world's lamest content farm at https://www.web.sp.am/. Click on a link or two and you'll get the idea,” he wrote. “Unfortunately, GPTBot has found it and has not gotten the idea. It has fetched over 3 million pages today. Before someone tells me to fix my robots.txt, this is a content farm so rather than being one web site with 6,859,000,000 pages, it is 6,859,000,000 web sites each with one page. Of those 3 million page fetches, 1.8 million were for robots.txt.”

Levine mostly finds this amusing, and said that the bot stopped crawling his site sometime Thursday afternoon after he made the post. But it does show the sort of indiscriminate scraping of the internet that OpenAI is doing to train its AI models. And it shows that GPTBot, which OpenAI says “may potentially be used to improve future models,” is scraping sites that are obviously nonsensical to humans. This is something that also became clear when a group of researchers was able to trick ChatGPT into spitting out some of its training data a few months ago.
“If you were wondering what they're using to train GPT-5, well, now you know,” Levine wrote in his post. OpenAI did not respond to a request for comment.
Levine said that in the past, both Bing’s crawler bot and an Amazon bot got stuck in the same sort of loop, and that this is at least the third spider that has been caught in the web.sp.am/., uhh, web.
“As is often the case, there are lots of things on the internet that look simple in principle, but in fact, are tricky in practice. And running web spider is one of them. Lots of spiders, like the Google Bot sort of drops by maybe once a day,” Levine told me. “All of these pages look the same and they’re all in the same IP address and they all share the same SSL certificate. It’s not really making an attempt to hide the fact that all 6 billion pages are really the same, but you actually have to have some experience doing this stuff [programming a crawler] to avoid hammering on people.”
Levine says he put the three ads on the page—two of his books, and a carton of fake eggs (“which were just cute,” he said) to see if anyone clicked them. “Nobody buys The Internet for Dummies anymore. It was wildly successful 30 years ago, but these days, everyone knows how to use the internet,” he said.
“Except OpenAI, in this case,” I responded.
“Well, you said it,” Levine said.
