

Companies are deliberately making their AI tools speak like cavemen in an attempt to stop burning through AI tokens and curb their massive expenditure on AI, 404 Media has found. The tool turns the usually verbose outpost of LLMs like Claude Code, Codex, or Gemini into a much more to the point answer. Think less “you’re right to push back, I was wrong,” and more “Hulk smash.”
Use of the caveman plugin is in direct response to the skyrocketing and unpredictable cost of AI. As 404 Media previously reported, companies are scrambling to stop spending so much on AI, with consulting giant Accenture finding much of the “soaring token spend” is thanks to people using AI to convert PDFs to presentations. People using caveman include developers at OpenAI, Nvidia, and GitHub, according to the tool’s creator. A senior OpenAI employee has even contributed code to the project, adding support for OpenAI’s Codex tool.
“I made Caveman back in early April because I was using Claude Code heavily and noticed a lot of my token spend was going to unnecessary prose: pleasantries, hedging, transitions, and chatty language that does not really matter inside an agent loop,” Julius Brussee, the creator of caveman, told 404 Media.
One company using caveman is electrical and digital infrastructure giant Legrand which, ironically, has entered the data center business. An internal Legrand memo shared with 404 Media tells employees “since the billing system changed and the new quotas were implemented, we all need to be mindful of our usage of AI so we don’t use up our entire budget allowance too quickly.” It goes on to list four things that will produce “high impact”: not always using the most powerful model; not always using high reasoning settings for the LLMs; using different more appropriate models for different tasks; and finally “use ‘caveman skill’ to reduce output consumption (without impacting code).”
In 404 Media’s tests of caveman with Claude Code, the plugin does make the LLM’s answers much more to the point. “Want changes to it?” the LLM asked after I told it to review some previously written code. “Uses official API, not scraping,” the LLM added, describing how the code worked. When I double checked caveman was installed Claude outputted, “Already active. What you need?”
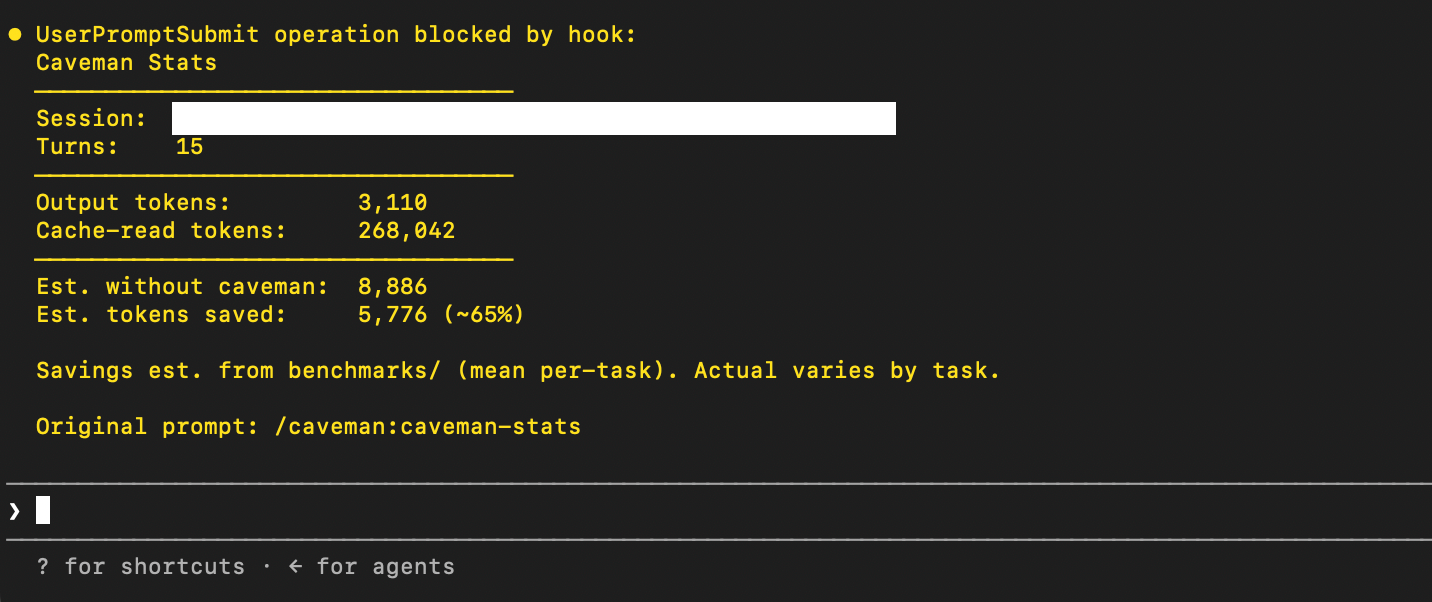
Caveman can also display what it says is the total number of tokens saved. In my case, caveman said it had saved me around 5,800 tokens, or 65 percent.
“It makes the model speak less like a polite chatbot and more like a terse tool,” Brussee said. “Same substance, fewer words. In my evals, Caveman cut output tokens by roughly 65–75 percent versus default verbose output, and still beat a normal ‘be concise’ instruction. That number varies by workflow, but the effect was clear.”
Caveman users can pick their level of “grunt”: lite, full (which is the default setting), ultra, or Wenyan, which translates the output into classical Chinese characters (I verified this works and now have no idea what the Claude output says).
“The goal was to reduce output tokens without touching the parts where exactness matters: code, commands, paths, URLs, numbers, function names, and technical details. Caveman mostly compresses the surrounding language,” Brussee added.
Records on GitHub show that Shayne Sweeney, director of engineering at OpenAI, has contributed code to caveman. A commit a couple of months ago says, “Add Codex plugin support.”
Caveman also offers a whole agent that condenses everything down to caveman language. “caveman-code shrink everything — full terminal coding agent, caveman top to bottom. ~2× fewer tokens than Codex on identical tasks. 20+ providers · plan mode · autopilot goal loop · MIT,” caveman’s GitHub repository says. Caveman can also be used with OpenClaw, the agentic AI tool that went massively viral earlier this year.
The plugin is obviously pretty funny but comes in response to a very real problem. In April, GitHub announced it was going to start charging customers per token rather than a flat subscription fee. Uber capped employee’s use of AI tools and the company’s CTO says Uber blew through its entire AI budget in just four months. Walmart also capped AI tool usage. And now you have companies using caveman.
“I’ve heard from many individual developers and engineers inside companies using or testing it, including people at OpenAI, NVIDIA, GitHub, and DEPT,” Brussee said.
In leaked audio obtained by 404 Media, Accenture positioned itself as the cure to this problem, even though it encouraged clients to adopt AI as quickly as possible in the first place. In that audio a senior employee said Accenture had a new opportunity with its clients “to really think about token economics.”
Last year OpenAI CEO Sam Altman suggested that people extending their own pleasantries to LLMs, like “please” and “thank you,” cost OpenAI tens of millions of dollars in electricity costs.
Legrand, OpenAI, Nvidia, and GitHub did not respond to requests for comment on their caveman use.
Caveman’s GitHub repository says near the end: “Caveman save you token, save you money.”
